BERT, Google’s most recent algorithm update. Released on 22nd of October and according to Google has affected 10% of all results. To put that into context its changed the results for 22 million(1) searches every hour. Moz, SEMrush, Ahrefs have had little change (2) in their rankings and forecasts, early speculation has pointed out that this is because BERT affects long tail results
Who Is BERT & What Does He Want From Me!
Google has labelled BERT as “understanding searches better than ever before”. 15% of quries Google receives every day have never been seen before and this poses an enormous task for engineers. It’s not that they are intricate questions and are difficult to answer it’s that the user more than likely has phrased the questions awkwardly making it difficult for Google to return the right answer. This is the issue Google wants to solve.
Google wants to have a conversation with you but we, as their users don’t tend to accept that and use “keyword-ese” phrases that we think Google will understand. If we were to speak like that to each other we’d have a tough time ourselves trying to communicate to one another.
Currently we know BERT will affect 1 in 10 of all searches made, we aren;t told by how much it will affect the results. We are also told that this hasn;t been rolled out to foreign languages yet but will over time.
Propositions like “for someone”, the verb “stand”, before Google couldn’t fully put these words into context. Before it didn’t understand whether “stand” related to a phrase or how it contextually changed the meaning of the sentence. If you googled a phrase with “stand”, google would have also brought back, stand-off, stand-alone and displayed the best results best on other keywords you looked for.
As a webmaster BERT wants you to continue doing what you’ve always done, he’s not going to penalise you he’s just going to forget about you if you’ve got spammy content, or content that people really don;t want to know about.
The Birth of BERT
In early November 2018 (possibly a little before then) Google released an open source programme called bert in GitHub (4)(it’s still live today if any developers want to play around with it). The aim of the project was to try and better understand users queries using something called Natural Language Processing or Understanding.
Subsequently, anyone in the world had the ability to train their own state-of-the-art question answering system in about 30 minutes on a single Cloud TPU (tensor processing unit or AI computer) , or in a few hours using a single GPU (graphics processing unit). (5)
As I’m sure you’re already aware BERT stands for Bidirectional Encoder Representations from Transformers but what do each of those words mean and how do they relate to each other.
- Bidirectional – this is simple enough, means something can go two ways
- Encoder – another way of saying this is software or a programme
- Representations – representing someone or something
- Transformer – Transformer in NLP (Natural language Processing) architecture solves sequence-to-sequence tasks while handling long-range dependencies. (long range dependencies in this case might be a sentence)(6)
Another way to write this that’s potentially easier to understand would be
A Two Way Programme For Recognising Sentence Structure – I much prefer BERT however.
What Does BERT Do & How Will It Affect Searches?
Bert didn;t come into existence overnight, it took a long training period and is the first unassisted NLP system. Bert basically learns how to read our language by understanding content, it crawls page after page of text to understand how words are grouped together and then stores this information. “BERT is a method of pre-training language representations, meaning that we train a general-purpose “language understanding” model on a large text corpus (like Wikipedia)” (4). BERT learnt how to read on Wikipedia and other sites similar. What’s worth noting here is that wikipedia isn;t optimised for search, yes they have titles and descriptions with keywords but the content isn’t optimised or stuffed. It’s a great training ground to understand context.
In May of 2019 a research paper (BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding) with the findings from BERT was released by Google AI Learning and published on Cornell University. Here they state “BERT is conceptually simple and empirically powerful”(7) which after spending some time breaking down how BERT works and what its produces I’d have to agree
“BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task specific architecture modifications” (8)
To break that down, before BERT, google was reading left to right as a human would to understand the context of a sentence. Because we can understand when a word is a verb and not a verb its easier for us as humans to understand context but Google has been struggling with this. Up until now the the term “stand”, which is a verb would be grouped with phrases such as “stand-off”, “stand-alone” as humans we know that the term stand is a verb and the other stand terms are nouns.
By google now being now able to read right to left through BERT it’s essentially doubling its understanding of the context someone might use a particular word for. There are also additional actions BERT can take to help it understand context, all of which we will break down below.
How BERT Works
BERT has multiple tasks to complete once a query is made but it can be broken down into two fundamental tasks it performs followed by a third, the output. If you can understand these tasks you’ll understand how BERT works.
TASK #1 – Masking
Masking is removing certain phrases from the query or basically ignoring them. I’m going to stick with the examples in the Google Webmaster Blog
“Can you get medicine for someone pharmacy”
Step 1: What BERT might do in this instance is Mask “Medicine” and “Someone”.
Step 2: Bert is going to search left to right through the internet for results using the Mask
“Can you get [Mask] for someone pharmacy”
Step 3: Bert is going to search right to left through the internet for results using the Mask
“Can you get medicine for [Mask] pharmacy”
In theory google could do this multiple times for all of the keywords to better understand content. All the time its trying to match sentences on webpages that might be the best result. Task two helps it identify the best result
Its also worth noting “Google Mask roughly around 15% of all wordpiece tokens”
Task #2 – Next Sentence Prediction (NSP)
Not only does BERT mask words within a query but when its searching for results it will look at the next sentence and based on its AI and analyzing the most common sentence after your query, its able to predict what you are talking about.
“In addition to the masked language model, we also use a “next sentence prediction”
Step 4: Analyse the following sentence for contextual placement
Again google could be taking this a step further and analyzing the sentence before as well
Task #3 – The Output
Can you get medicine for [Mask] pharmacy. Bert might have found sentences similar to the below.
Can you get medicine for a family member in the pharmacy.I collected a prescription from the doctor . . . .
Can you get medicine for another person pharmacy. My girlfriend needs me to collect her prescription what do I need . . .
Can you get medicine for a relative at the pharmacy. My uncles unable to drive and needs his prescription filled . . . .
Because google can now see that by removing someone from the sentence it gets a lot of results. Then it uses the second sentence as a contextual argument allowing it to understand and deliver much better results answering your deep questions.
“Many important downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between two sentences, which is not directly captured by language modeling.”
My own search for “Can you get [Mask] for someone pharmacy” revealed nothing and google would have struggled with this query. And you can see in the results from the before and after BERT update google would have returned a result that told you how to fulfill a prescription.
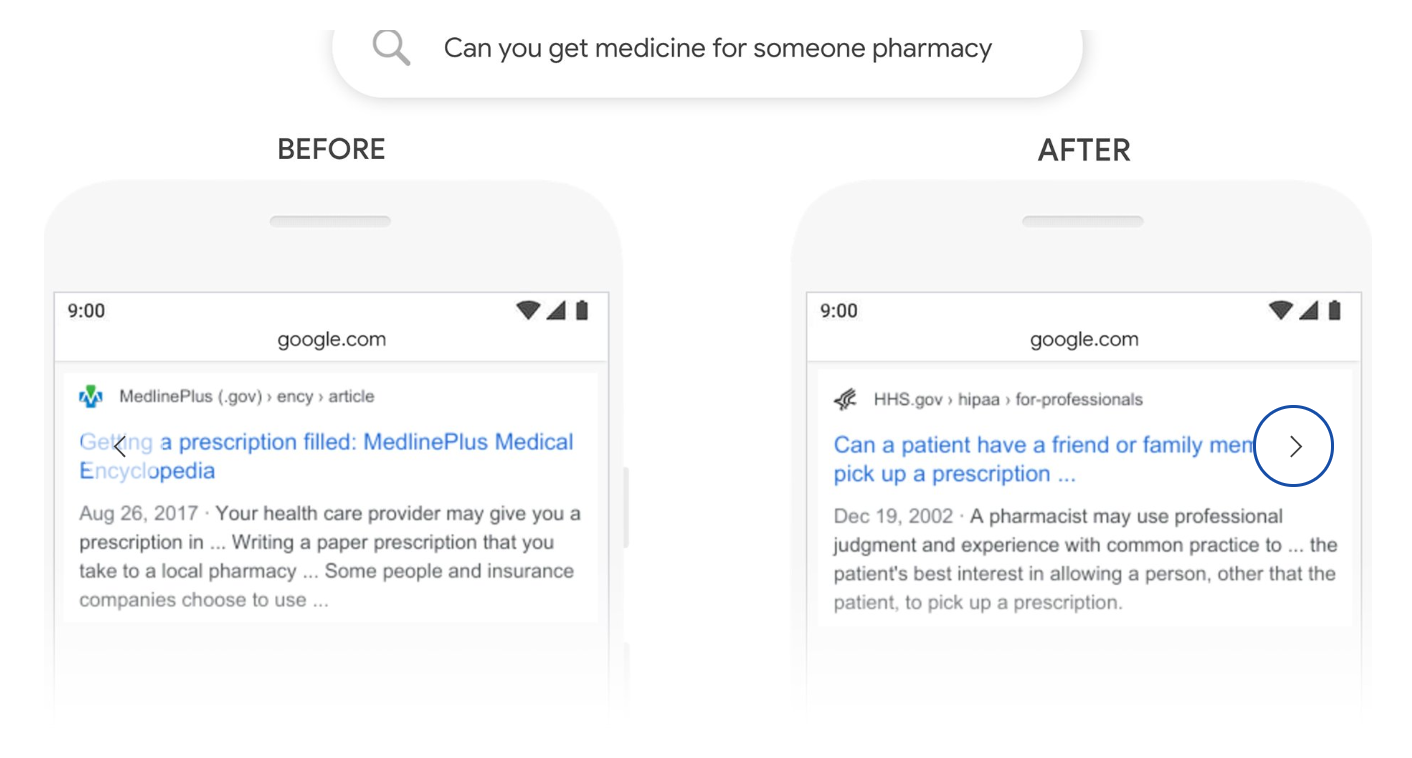
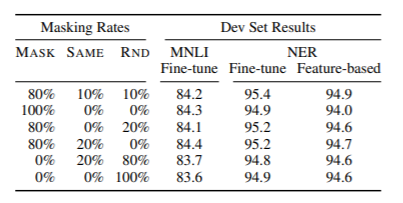
Google admittedly won’t always have the answer and even stated “Even with BERT, we don’t always get it right”. As a result when they output their results they split the findings 80% masked match, 10% unmasked and 10% semantic. They found these results to answer the question 95.4% of the time. (8)
What Did We Have Before BERT
We currently only have “OpenAI GPT, the authors use a left-to right architecture, where every token can only attend to previous tokens in the self-attention layers of the Transformer “
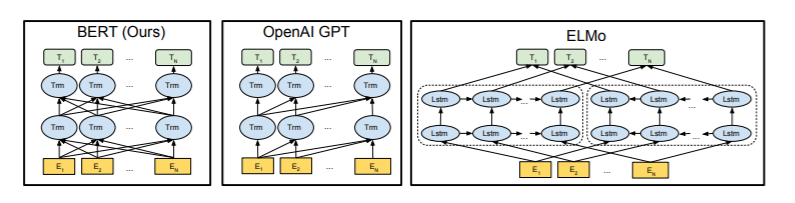
You can see in the diagram above (8) how BERT can read from left to right and right to left and really any way in which it wants in order to work out what makes the most sense. Before using the Open AI GPT its very hard for any computer to interpret what someone might want especially if they are using keyword-ese phrases
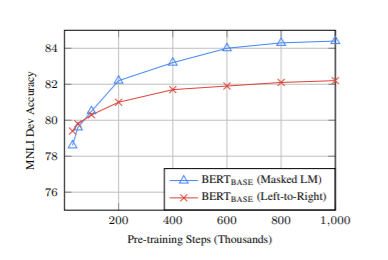
As you can see there is a significant increase in success rate when BERT was switched to using masking and given the ability to read right to left.
What Can We Learn From BERT
BERT isn’t going to affect you queries that you are tracking, these are often 2 or 3 word phrases. Google understands the users intent, it’s pretty straight forward. BERT is only going to affect long tail keywords, those intricate questions where not understanding intent would be hard, particularly keyword-ese phrases.
Looking at your rank tracker isn’t going to show anything, you need to be looking at search console and google analytics to make sure your organic traffic is up. Its much more likely that you’ll lose blog traffic or if you’re an information site you might lose traffic.
From what I’ve learned so far, BERT only affects On-Page SEO factors, other factors such as links and popularity are still a factor and you need to watch these metrics as much as your on page content
Keyword placement, to do it or not to do it. There are many people telling you that there is no way to optimise for BERT and to a certain extent they are right. Trying to keyword stuff a page for this sort of artificial intelligence is futile and only going to cause more damage than its worth. You will, however, still need to include your keywords in your article. From my understanding of how results are going to be returned, if your article doesn’t mention the phrase somewhere, google more than likely won’t rank it.
Latent semantic indexing has been debunked numerous times by SEO fanatics and google has even said themselves it doesn’t exist. I think that when people mention LSI, this is what they are referring to, it may not be what google calls it but this is essentially what people are referring to.
We’re heading towards a more user friendly voice search world. With sales of google home and mini increasing steadily and voice search being on everyones phone its only a matter of time before people start consistently using it over traditional search methods making search phrases even more diverse and harder to return an exact result
You still need to optimise your content, yes write for a human but don’t forget it’s still going to be a robot delivering the result. You need to understand how to choose content and optimise.
What Can We Expect Of BERT Over The Coming Years
BERT could actually be better, the open source projects states that their tests were limited by RAM and BERT could potentially learn more if they were able to store more ram.
Googles quantum computer (9) I’m assuming wasn’t used in this experiment and therefore I’m predicting that as they can update their systems BERT is only going to get stronger. They’ve also mentioned this in the PR release (3) “But it’s not just advancements in software that can make this possible: we needed new hardware too. Some of the models we can build with BERT are so complex that they push the limits of what we can do using traditional hardware”
I expect that this is only the beginning of AI and BERT will developed significantly during the 2020’s to deliver better results and help the SEO community match users needs.
References
- https://www.google.com/search?q=how+many+searches+are+made+by+google+every+day&rlz=1C1CHBF_enIE791IE791&oq=how+many+searches+are+made+by+google+every+day&aqs=chrome..69i57j0l2.9447j0j7&sourceid=chrome&ie=UTF-8
- https://searchengineland.com/why-you-may-not-have-noticed-the-google-bert-update-324103
- https://blog.google/products/search/search-language-understanding-bert
- https://github.com/google-research/bert
- https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
- https://www.analyticsvidhya.com/blog/2019/06/understanding-transformers-nlp-state-of-the-art-models/
- https://arxiv.org/abs/1810.04805
- https://arxiv.org/pdf/1810.04805.pdf
- https://www.cnet.com/news/google-quantum-computer-leaves-old-school-supercomputer-in-dust/